
How a Jeopardy! Champion Remembers Everything
One of Jeopardy's winningest players talks about how he studied for the show and how he organizes his life
September 6, 2019

Roger Craig isn’t your average Joe.
He’s a machine learning, data science, and AI practitioner who combined his computer skills and an interest in quiz games into something extraordinarily unique:
He won more than half a million dollars on Jeopardy!, including a whopping $77,000 in a single day.
He did this not just with raw intelligence, but by creating a system to help him fashion himself into a game-show superstar.
In this edition of superorganizers Roger tells us:
- How he used NLP to statistically analyze the Jeopardy! Archive
- How he used spaced-repetition through Anki to help him memorize the vast of amounts of knowledge he needed to win
- How he uses Polarized to help process and take notes on PDFs on his computer
- How he builds up a library of bookmarks to help him create a diary of everything he’s ever consumed
I’m psyched to get to the meat of the interview. Let’s dive in!
How he got started studying to compete for Jeopardy!
Everything I did for Jeopardy! was very organic. I was always into quiz games, and I had played Quiz Bowl in college.
But I didn’t go into it wanting to do everything I ended up doing. Initially I wanted to figure out, “What is the percentage of Shakespeare questions on the show?” or “What is the percentage of US Presidents?”
So I built a system to do that, and I started sharing what I had done with some of my friends. And then one of them said, “ it would be great if you made a little game of solitaire where you could just play an episode.”
And it built organically from there.
How he studied for Jeopardy!
I started by downloading the Jeopardy Archive and using that to study for the show.
Essentially, it's too much information for someone to absorb, in a traditional way. So I had to bring order to that chaos. I did that by starting to categorize the clues using natural language processing or text mining.
At a basic level, it's download, scrape, normalize it, get it into some relational database, and then cluster everything.
Once you do that you can start to see what kinds of questions get asked on the show. Once you understand the statistical distribution of questions on the show, the next question is: where are your strengths and weaknesses?
So I built a front end where I could start to label the data. I could just go over these questions and say, “Do I know the answer yes, or no?”
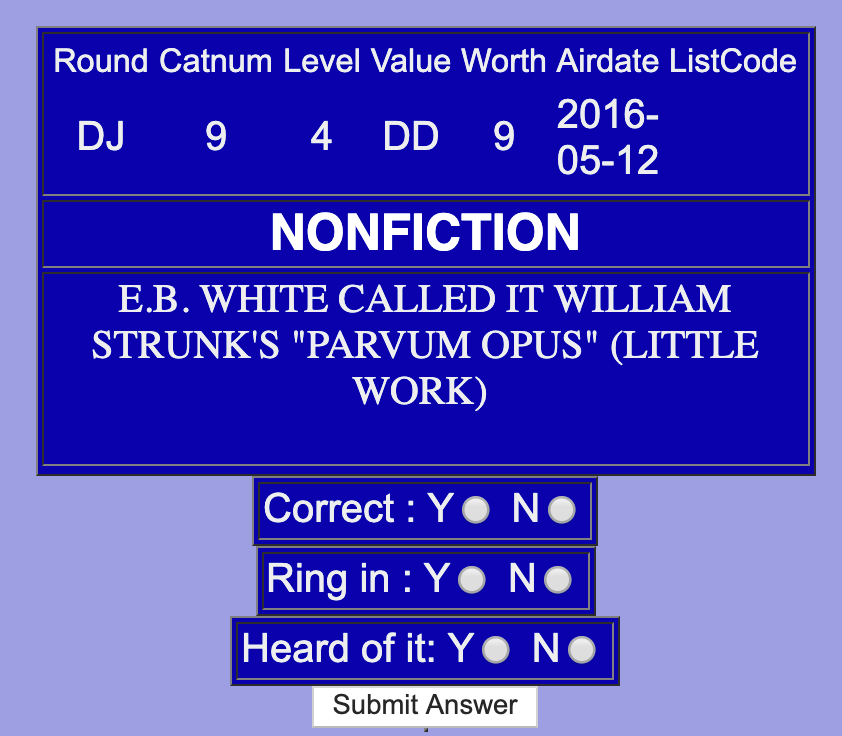
Once you have that labeled data then you can start to build models of it, and you can start to see where your strong points and weak points are, and go accordingly.

Then once I had the initial labeling done, I used spaced repetition to help me study for the show. I leaned on Anki for that.

Basically, I used scripts to generate decks of cards from the data I had collected. I had tons and tons of these decks that I used to study.
Spaced repetition software builds a model of what you know, don’t know, and what you’re likely to forget. Then it helps you get from where you currently are to where you want to go because it keeps bringing cards up that you’re likely to forget to help them stick in your mind.
You’re building a model of the present built off the past. And you’re using that to, hopefully, predict the future.
How he keeps track of notes with his command line and Git
I'm probably not the most organized person. What I try to do is take better notes and record things where I can go find them later.
Because in the past 10 years, especially with the advent of smartphones, we're so bombarded with information. There’s so much of it that it becomes harder and harder to remember you even heard something.
One thing I do is I have little scripts on my computer that allow me to take notes right in my command line. And the notes get saved to a text file on whatever machine I’m on. Then from there, the notes are tracked in a Git repo and synced to the cloud.
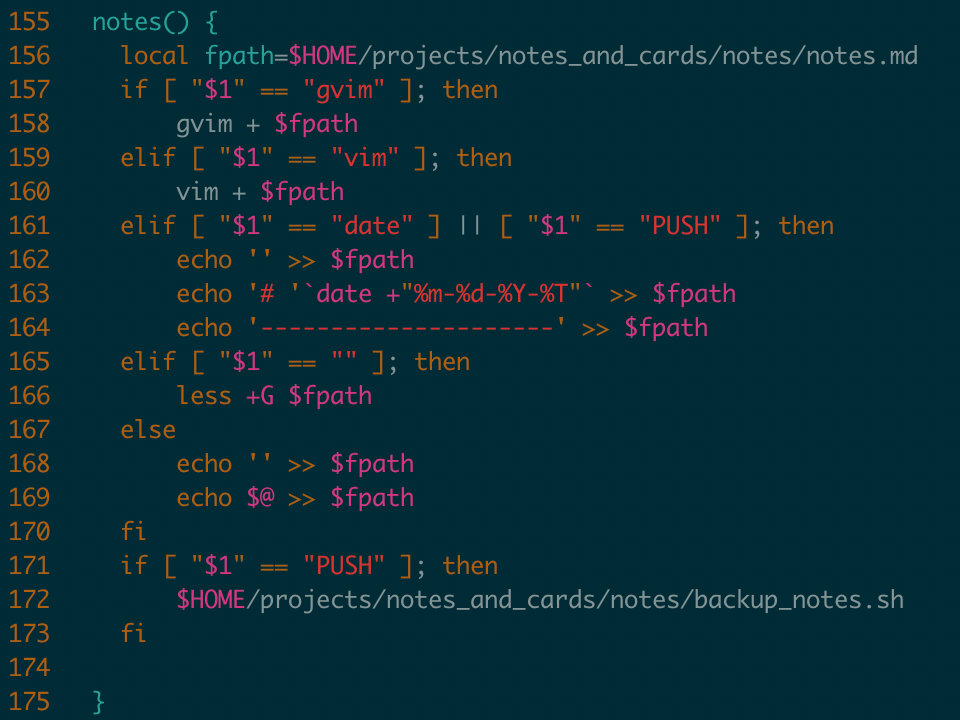
The advantage of that is that each note becomes timestamped, and Git provides a central source of source of truth for all of my notes.
So that helps me keep track of everything from todos, to things I want to read, to things I want to scrape. There’s a set of verbs that I use for this — it’s not super large, it's probably half a dozen to a dozen — but it’s things like: to do, to read, to scrape, etc.
It's not the most user friendly at times, but it’s not something that’s going to disappear anytime soon.
A lot of this stuff is actually to help me remember things as a programmer. Because as a programmer, if your memory isn't good, or you do something but then you don't do it again for like a month or two, you're usually going to forget it.
So if I find myself on the same Stack Overflow page multiple times I’ll just save it so I have it available.
For certain notes, I’ll actually turn it into a flash card in Anki. For example, I have flash cards around how to do something in Bash, or how to do something in Javascript. By turning it into a flash card and reviewing it periodically, it helps me remember it when I need it.
How he uses Polarized to save and take notes on PDFs
The next tool I use is called Polarized. A lot of the information I consume is in technical published papers, which are in PDFs, and Polarized helps with that.
It takes in PDFs and web pages, and allows you to highlight and annotate them. You can also export them, so you can turn the annotations into Anki cards.
So basically every paper that is of interest to me, I save it into one big directory, and then Polarized goes in and ingests all of the papers and makes them available for me to read and annotate.
How he uses bookmarks to keep a diary of everything he’s ever consumed
The other thing I tend to work with is my bookmarks.
Not many people know this but you can actually download your Chrome bookmarks and work with them programmatically. That's a powerful tool.
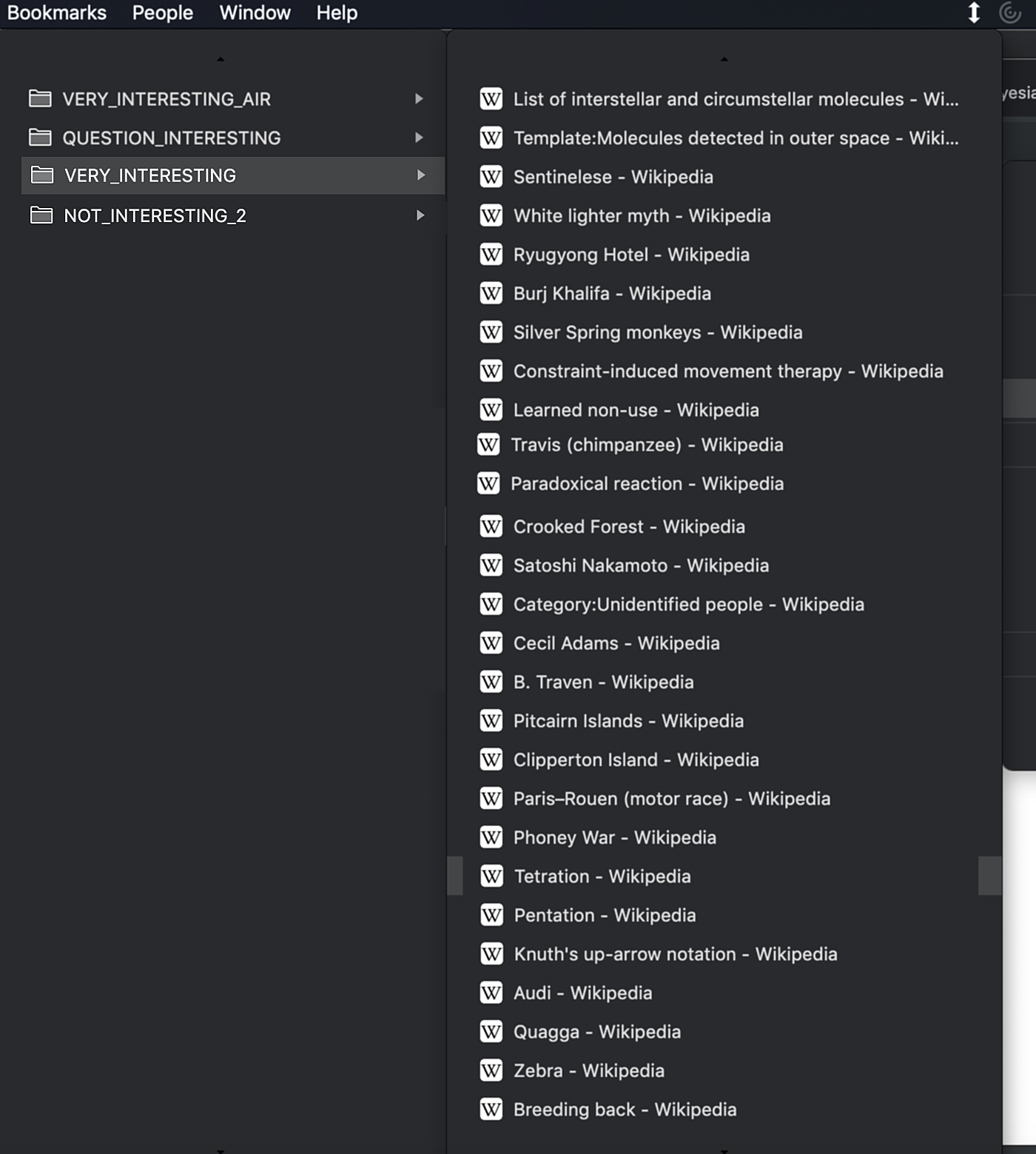
What I realized after getting into natural language processing is that, to some extent, categorizing your bookmarks according to generic, high-level categories is not a good use of time. Because eventually we’re going to have automated systems that do that for us, so why even bother?
By the same token, we don't have to categorize our music into genres, because you can use services that tell you, okay, Bruce Springsteen is, rock or whatever.
I sort bookmarks based on categories that are highly personal to me that aren't available in some public data set or knowledge base.
These are mostly news articles, or information-based articles. Anything that’s of interest to me.
The point of this is not to ever go back and refer to these, the point is just to capture data. I’m very interested in capturing the semantic signal of what I'm interested in.
It’s kind of like having a diary of everything I’ve ever consumed.
On occasion, I even bookmark things that are uninteresting to me, and put them in an “Uninteresting” folder, because I use this as a way to label data on my own, and then build up data sets for that.
Another reason I do this is that I don't like the idea that these tech companies have a signal on me, but I don't have a signal. This is my effort to try to build that up.
How he builds his own version of Wikipedia
One thing I do is a trick from a guy I know in the quiz culture, where he said that every time he reads an article on Wikipedia that he finds interesting, he bookmarks it.
I’ve starting doing that as well, and just having that memory of that is pretty valuable. Because, Wikipedia has organized an incredible amount of knowledge in the past two decades.
And it’s interesting because I think the biggest drawback of Wikipedia is that it's too big, it's too complete.
When you have an encyclopedia with 5.8 million articles, you could live 100 lifetimes and never read them all.
So for each person, what are the 58,000 or 5800 articles that they might be interested in? That's something that's really interesting to me, and bookmarking Wikipedia articles is a good process for me to collect the portion of Wikipedia that’s specifically relevant or interesting to me.
Forgetting isn’t always a bug
One comment I wanted to make about organization and knowledge is that forgetting things, it’s not always a bug.
Sometimes collecting these things has utility beyond just understanding. I think a good example of that is LastFM. I got on LastFM over a decade ago, and it’s tracked most of the music I’ve listened to in that time. That means I can look at my music going back the last 10 plus years of my life.
And that's fun, just from the fact that I love music, and I can go and see the songs and see the patterns in what I like and don’t like.
It brings up for me the question: why do we do these things? Is it to become more efficient or make more money? Or is it to become happier? What you know? And what is the purpose of it all?
Self knowledge is a good thing. You know, know thyself.
And on that note, let me tell you a story. So I came in third in the finals against Ken Jennings and Brad Rutter in the Battle of the Decades in 2014.
And one of the Daily Doubles I missed was about edema or something. And I totally knew the answer. I just couldn't think of it at the time.
And then I went back in my database. And I could find a question that was almost exactly the same. And I had answered it correctly, in 2010, at this exact timestamp, and it was like, well, I knew it, then. Ha. So that was a little Monday morning quarterbacking.
On whether your notes should be organized like a library or the junk drawer in the kitchen
When it comes to taxonomies there’s two approaches: there’s say the library shelving approach, and the junk drawer in the kitchen approach.
The library shelving approach says every piece of data should be in a particular place in your organization system. That’s often accomplished by tags. So you can go into your system and create a bunch of tags. But the problem is that the taxonomy you create will change over time: you’ll want to merge tags or split them. And that creates a lot of overhead.
The junk drawer approach says, “Don’t even bother creating a taxonomy, let’s just use search.” And that can be good too, but it doesn’t at all deal with creating a structure.
I actually do the middle path. I kind of throw everything together, because I know I'm going to do search. And if there’s some obviously good tag for it, that’s something personal to me, I’ll tag it. But if not, that’s fine, because to come back to the machine learning, if you have all that unlabeled data you can then go back, and then try to bring order to that chaos and cluster things together, and automatically tag them.
On not letting optimization take over your life
Yeah, I would just say one thing, what I would caution is: don't let optimizing or organizing take over your life. People spend more time optimizing and organizing than doing the thing that they're supposedly optimizing or organizing.
Books he recommends
There are a few I’d recommend. First is Flow, by Mihaly Csikszentmihalyi.

But I’d also recommend Influence, by Robert Cialdini. And Deep Work, by Cal Newport.
Thanks for reading! I would love to know what you think about this issue. Hit reply, and send me some feedback! Or forward to the superorganizer in your life who you think would most want to read this.
Find Out What
Comes Next in Tech.
Start your free trial.
New ideas to help you build the future—in your inbox, every day. Trusted by over 75,000 readers.
SubscribeAlready have an account? Sign in
What's included?
-
 Unlimited access to our daily essays by Dan Shipper, Evan Armstrong, and a roster of the best tech writers on the internet
Unlimited access to our daily essays by Dan Shipper, Evan Armstrong, and a roster of the best tech writers on the internet
-
Full access to an archive of hundreds of in-depth articles
-
-
Priority access and subscriber-only discounts to courses, events, and more
-
Ad-free experience
-
Access to our Discord community

 Scott Nover
Scott Nover



 Evan Armstrong
Evan Armstrong

Comments
Don't have an account? Sign up!