
What Are AI Agents—And Who Profits From Them?
The newest wave of AI research is changing everything
September 23, 2024
Each quarter, Every tells its writers to put down their pencils, stop scribbling, and think. We call these our Think Weeks, and they’re phenomenal opportunities to take a break from the daily hustle, step back, and look at the evolving tech and business landscape. Ahead of OpenAI’s DevDay taking place on October 1, we thought this was a perfect time to republish some of our sharpest writing on ChatGPT. First up, Evan Armstrong’s look-ahead about AI agents, which feel closer to reality than ever.—Kate Lee
Was this newsletter forwarded to you? Sign up to get it in your inbox.
Most races have a prize pool. The New York City marathon winner gets $100,000. The F1 winner in 2023 took home a $140 million pot.
The winner of the race that I’m going to describe will earn billions. Maybe tens of billions. They’ll bend the arc of the universe. They’ll materially increase the GDP of entire countries.
This is the race toward the AI agent. Agents are the next step in the AI race and the focus of every major tech giant, AI startup, and research lab.
I’ve spent months talking with founders, investors, and scientists, trying to understand this technology. Today, I’m going to share my findings. I’ll cover:
- What an AI agent is
- The major players
- The technical bets
- The future
Let’s get into it.
What is an agentic workflow?
An AI agent is a type of model architecture that enables a new kind of workflow.
The AI we started with formulates an answer and returns it to the user. Ask it something simple, like “Does an umbrella block the rain?” and OpenAI’s GPT-4 returns the answer, “Of course it does, you dumbass.” The large language model is able to answer the question without relying on external data because it uses internal data and executes on the prompt without making a plan. It's a straightforward line connecting input and output. And every time you want a new output, you have to provide a fresh prompt.
Agentic workflows are loops—they can run many times in a row without needing a human involved for each step in the task. Under this regime, a language model will make a plan based on your prompt, utilize tools like a web browser to execute on that plan, ask itself if that answer is right, and close the loop by getting back to you with that answer. If you ask, “What is the weather in Boston for the next seven days, and will I need to pack an umbrella?” the agentic workflow would form a plan, use a web browsing tool to check the weather, and use its existing corpus of knowledge to know that, if it is raining, you need an umbrella. Then, it would check if its answers are right and, finally, say, “It’ll be raining (like it always does in Boston, you dumbass) so, yes, pack an umbrella.”
What makes an agentic workflow so powerful is that because there are multiple steps to accomplish the task, you can optimize each step to be more performative. Perhaps it is faster and/or cheaper to have one model do the planning, while smaller, more specialized models do each sub-task contained within the plan—or maybe you can build specialized tools to incorporate into the workflow. You get the idea.
But agentic workflows are an architecture, not a product. It gets even more complicated when you incorporate agents into products that customers will buy.
Solving users problems > flashy demos
The only thing that matters in startups is solving customers’ problems. Agentic workflows are only useful as a product if they solve problems better than existing models. The tricky thing is that no one knows how to make AI agents a consistently better product right now. The pieces are all there, but no one has figured out how to put them all together.
This moment is strongly reminiscent of the early 1980s of personal computing, when Apple, Hewlett-Packard, and IBM were duking it out. They all had similar ideas about user interface (the use of a mouse, the need to display applications, etc.), but the details of implementation were closely guarded secrets. These companies competed on the quality of their technical components and how each of those components fit together to solve customer problems.
Companies that make AI agents are competing both on individual component quality and how these components are combined. In broad strokes, think of these arenas of competitive intensity scattered across five components:
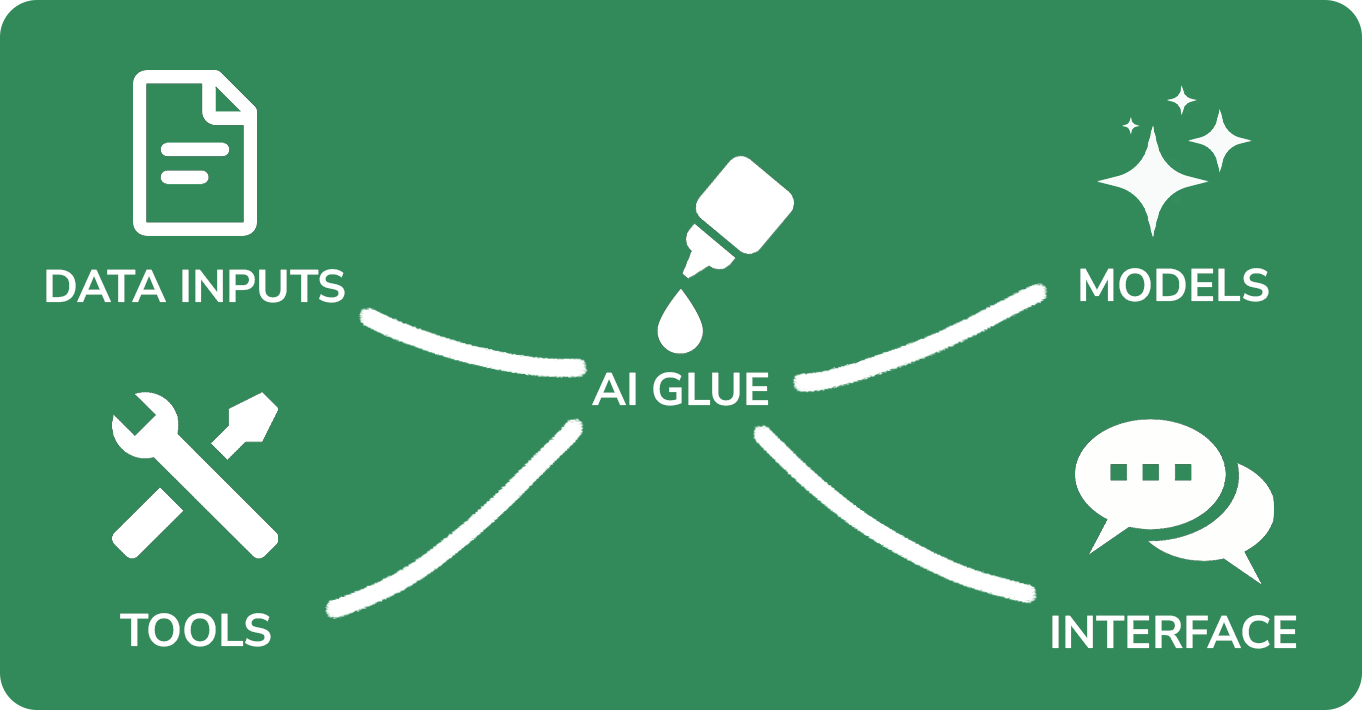
- Data inputs: The agent needs access to unique data sets or be better able to parse public data sets (such as scraping the web). Where does the agent draw its data from? Can it access internal data repositories—note-taking systems for individuals or corporate knowledge bases for enterprise use cases—to make answers better?
- Models: For the past year, when you heard “AI,” it typically meant this component—the LLMs like GPT-4. Within the model companies like OpenAI, there are a variety of approaches that I’ll cover in a minute.
- Tools: Think of these like giving the handyman (an LLM) a new set of screwdrivers. This is an area I’m excited about. In 2023, I used a tool from OpenAI called Code Interpreter that has been able to replace many finance workflows. Code Interpreter provides the LLM with a coding environment that allows the LLM to modify spreadsheets.
- Interface: Knowing how to integrate these capabilities into a user’s workflow is just as important as—if not more than—what the agent can actually do. Is the agent nestled within a typical LLM chatbot? Is it operating behind the scenes as part of an application's code? Does the AI need to be in its own separate UI and app? Or should it be integrated into an existing workflow app like Salesforce or Excel?
- AI glue: This is my own term (you can tell because it sounds dumber than the rest), but in my interviews with founders building AI agent companies, the most common thing I heard was that “AI agents are an engineering problem, not an AI problem.” There is a sense that while each of the previous components is important, what matters is figuring out how to stick them all together. Glue is traditional, deterministic software that programs a set of logical steps.
There are infinite combinations of these components. Unlike with previous generations of software companies, investors and founders are underwriting science risk as well as product risk. In the 2000s era of SaaS, we knew the cloud worked, and we knew how to make software on it. The only question was if you could make a product that used the cloud in a way that benefited customers. With agents—both tooling and models—we haven’t completely figured out the science of making it work, let alone the product.
That is a mouthful, so let me repeat myself as simply as possible: This shit does not currently work, but investors are betting it can. Many assume we are just one or two scientific advancements away in models or tooling to make agents available at scale.
How do AI agent companies compete?
Well, actually, agents do, kinda, work—but only about 10 percent of the time. For context, a much-celebrated startup called Cognition Labs was able to solve 14 percent of “real-world GitHub issues found in open-source projects.” Not great, but, much better than its peers.
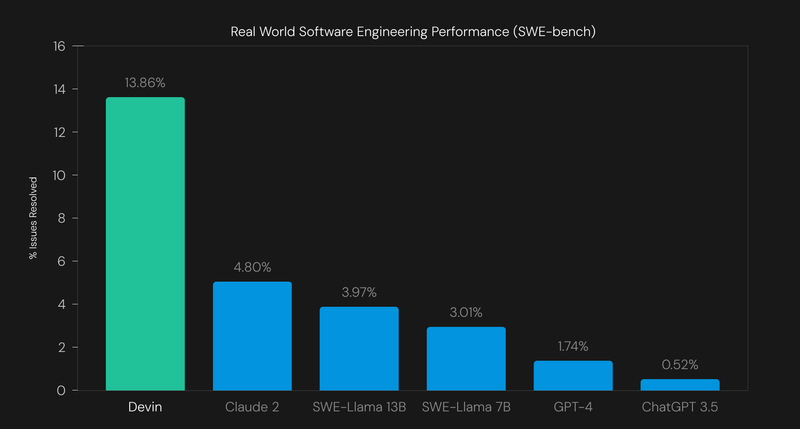
Investors are betting that founders can both make the technology work right, and make a product that adequately incorporates that tech. There are some low-level agent workflows with GPT-4 that you can do with ChatGPT (like my weather example from earlier), but AI agents are nowhere close to taking over all existing knowledge worker labor. It’s the inverse SaaS problem: The value is obvious, the ability to deliver a product dubious. In SaaS, the opposite is true: The value is typically non-obvious, and companies compete on their ability to sell products.
Bear in mind that all five of these components are just to make the thing turn on! Once companies can use AI agents to solve a problem for users, they then have to compete against each other—and LLMs, and all the other software tools. Speed, cost, and reliability are the important factors. AI agents need to be significantly cheaper—and equally, if not more reliable—than human labor to fully replace existing solutions.
This raises another question: How do you evaluate the damn things? As we’ve previously argued, evals to compare AI products are fundamentally broken. We barely have the language to discuss artificial intelligence, let alone the type of rigor required to compare products.
What we do have is capital—and we can look at where it is going to understand how the markets think value will accrue.
Follow the money
One of the great tragedies of AI agents is that the products are being built in secret. From 2015-2020, there was a strong culture of publishing research papers on AI, so scientific progress was shared. Now that billions are on the line, that has changed. We are stuck doing guesswork based on funding.
There are two main types of AI agent companies:
1. Model-first startups: These companies are betting that the model component is the most important part of the tech stack, and there are large gains to be had in improving LLMs. They’ve raised large amounts of capital to subsidize the cost of building these models. Here are the leaders:
- OpenAI ($13 billion-plus raised): It is reportedly already building a personal assistant for work that can take over the mouse of users to click things, transfer data, etc. It’s taken minor steps towards agent workflows with the GPT store but has yet to release a fully featured, properly branded AI agent product. The company is in the midst of prepping for the GPT-5 release.
- Anthropic ($7.3 billion-plus raised): It’s following the same strategy as OpenAI, but it’s smaller and in second place. The company hasn’t made any explicit product announcements around agents, but I’ve heard whispers it’s also conducting agent research.
- Adept ($413 million raised): Adept is betting that a new type of model is required—one that’s trained on user actions. The AI learns from watching how users interact with their browsers.
- Imbue ($220 million raised) and Magic AI ($145 million raised) are both focusing on software engineering AI agents and are training their own models.
The fundamental question that these startups are trying to answer is what type of model is right. Is it a super-powerful model like GPT-5? Is it a user-action model like Adept? Is it a reasoning- and code-first model like Imbue and Magic? No one knows! And that's the fun part.
2. Workflow applications: These companies use existing models and are betting that the other components (like glue and UI) will end up being the most important.
We can put these companies on a spectrum: On the left-hand side is “vertical task automation,” and on the right is “horizontal selling of AI agents.” A vertical work application automates a variety of tasks within one industry—think AI agents for legal, like Harvey ($80 million-plus raised). In the middle are AI agents geared toward one specific task, such as software engineering. Cognition Labs ($20 million-plus raised) focuses on performing one large task—writing code—that cuts across many industries. On the far right are companies that sell AI agents as a service. You pay to access AI agents that can do a variety of horizontal tasks, like calendering, note-taking, or PDF summary. Lindy ($50 million raised), which offers a tool that has dozens of AI agents, is an example of this kind of company. There are many of these players, and arguably, every software company could be an AI agent company.

None of the workflow automation companies have trained their own models—they use open-source or other private providers. When I chatted with Lindy CEO Flo Crivello about his company’s decision to not train a model, he told me:
“My rough mental model on these models is that they're like CPUs—they're getting exponentially better, are more or less general-purpose (the best model tends to be the best at everything), and cost an absolute fortune to train (don't try this at home). And I think there's more than enough work with the product and engineering side of agents to not have to worry [about] trying to build your own foundation models on top of that. Now, where that mental model breaks is that you also can very much get a nice performance bump on any model, if you fine-tune it on your specific task (which we're doing). But that's a different thing entirely from training foundation models.”
The more reliant a task is on a large and private dataset, the more likely it is that a workflow application will be dominant instead of a model. The best software companies function as a system of record, a repository for the most important data (customer IDs, product analytics, or credit card numbers), and they’ll be able to offer superior products. However, if the dataset is small—say, just a spreadsheet—it’s easy to drop that into a model-first company’s environment. Have a spreadsheet problem? Upload it to ChatGPT. If it turns out that models are a long-term differentiator, it may be easier for the first category of providers to build workflow software than vice versa.
Whichever bet investors are making on components, there is one meta-risk that hangs as a dark and vengeful god over the entire industry: scaling laws.
The problem with compounding growth
One of the miracles of the modern age is Moore’s law: the observation that the number of transistors on a chip doubles approximately every two years, leading to an exponential increase in computing power and efficiency. Our computers have become ever more powerful for nearly 60 years.
What people forget is that, as these chips grew more powerful, the cost of data processing became dramatically cheaper.
A similar phenomenon appears to be happening in large language models. The cost-per-unit of intelligence is heading markedly down. For example, Anthropic’s Claude 3’s Haiku model is one-quarter of the cost of OpenAI’s GPT-4 Turbo while simultaneously surpassing GPT-4 on user-rated benchmarks of intelligence. At a certain point, the models will become so all-powerful and intelligent that tools, data, UI, and glue will become moot. There is an inverse relationship between the levels of supplemental code and intelligence in the model: The more code, the dumber the model can be; the less code, the smarter the model must be.
As for when (if?) we reach the point where all the other components besides models are pointless, it is anyone’s guess. If you believe the scaling hypothesis—that the bigger the models get, the closer we get to superhuman intelligence—then there is a clear path to get there.
One final word of caution: As you look at these companies’ demos, it is easy to be skeptical and dismissive. The error rates are high, and like I said earlier, they don’t really work. But AI is an industry of compounding improvement curves. Early reports of GPT-5 are that it is “materially better” and is being explicitly prepared for the use case of AI agents. Last year Anthropic told its investors it was preparing to create a model 10 times better than GPT-4. If it holds to its timeline, that model should be finished this year.
If these forecasts hold up, there will be an abundance of spooky-smart, spooky-cheap intelligence. Agents are the next thing, and they are coming sooner than you think. Get ready.
Evan Armstrong is the lead writer for Every, where he writes the Napkin Math column. You can follow him on X at @itsurboyevan and on LinkedIn, and Every on X at @every and on LinkedIn.
Find Out What
Comes Next in Tech.
Start your free trial.
New ideas to help you build the future—in your inbox, every day. Trusted by over 75,000 readers.
SubscribeAlready have an account? Sign in
What's included?
-
 Unlimited access to our daily essays by Dan Shipper, Evan Armstrong, and a roster of the best tech writers on the internet
Unlimited access to our daily essays by Dan Shipper, Evan Armstrong, and a roster of the best tech writers on the internet
-
Full access to an archive of hundreds of in-depth articles
-
-
Priority access and subscriber-only discounts to courses, events, and more
-
Ad-free experience
-
Access to our Discord community
 Evan Armstrong
Evan Armstrong


Comments
Don't have an account? Sign up!