
Sponsored By: Notion
This essay is brought to you by Notion, your all-in-one workspace solution. Startups can now enjoy 6 months of Notion Plus with unlimited AI, a value of up to $6,000—for free! Thousands of startups around the world trust Notion for everything from engineering specs to new hire onboarding. Access the limitless power of AI right inside Notion to build and scale your company.
When applying, select Every in the drop-down partner list and enter code EveryXNotion at the end of the form.
I’m working on a series of pieces trying to create a map of the psychology and behavior of language models: compression, expansion, translation, and remixing.
I realized that in order to write it, I needed a clear, lower-level explanation about how language models work. In other words, I needed to write a prequel to my piece about language models as text compressors, a Phantom Menace of this series, if you will (except, hopefully, you know, good). This is that article.—Dan Shipper
Was this newsletter forwarded to you? Sign up to get it in your inbox.
If we want to wield language models in our work and still call the results creative, we’ll have to understand how they work—at least at a high level.
There are plenty of excellent guides about the internal mechanisms of language models, but they’re all quite technical. (One notable exception is Nir Zicherman’s piece in Every about LLMs as food.) That’s a shame because there are only a handful of simple ideas you need to understand in order to get a basic understanding of what’s going on under the hood.
I decided to write those ideas out for you—and for me—in as jargon-free a way as possible. The explanation below is deliberately simplified, but it should give you a good intuition for how things work. (If you want to go beyond the simplifications, I suggest putting this article into ChatGPT or Claude.)
Ready? Let’s go.
Let’s pretend you’re a language model
Imagine you’re a very simple language model. We’re going to give you a single word and make you good at predicting the next word.
I’m your trainer. My job is to put you through your paces. If you get the problems right, I’ll stick my hands into your brain and futz around with your neural wiring to make it more likely that you do that again in the future. If you get it wrong, I’ll futz again, but this time I’ll try to make it more likely you don’t do that again.
Here’s a few examples of how I want you to work:
If I say “Donald,” you say: “Trump.”
If I say “Kamala,” you say: “Harris.”
Now it’s your turn. If I say “Joe,” what do you say?
Seriously, try to guess before going on to the next paragraph.
If you guessed “Biden,” congrats—you’re right! Here’s a little treat. (If you guessed wrong, I would’ve slapped you on the wrist.)
This is actually how we train language models. There’s a model (you) and there’s a training program (me). The training program tests the model and adjusts it based on how well it does.
We’ve tested you on simple problems, so let’s move on to something harder.
Startups receive 6 months free of Notion Plus with unlimited AI, valued at up to $6,000! Notion is the go-to workspace for thousands of startups worldwide, helping them manage everything from engineering specs to new hire onboarding to fundraising. With Notion Plus, access the limitless power of AI to streamline and scale your operations seamlessly. Simplify your processes and enhance productivity with one powerful tool.
Apply now and select Every in the drop-down partner list, then enter code EveryXNotion.
Predicting the next word isn’t always so simple
If I say “Jack,” what do you say?
Try to guess again before going on to the next paragraph.
Obviously, you say: “of” as in, “Jack of all trades, master of none! That’s what my mom was afraid would happen to me if I didn’t focus on my school work.”
What? That’s not what immediately flashed through your mind? Oh, you were thinking “Nicholson”? Or maybe you thought “Black.” Or maybe “Harlow.”
That’s understandable. Context can change which word we think will come next. The earlier examples were the first names of celebrity politicians followed by their last names. So you, the language model, predicted that the next word in the sequence would be another celebrity name. (If you thought of “rabbit”, “in the box”, or “beanstalk” we might need to futz around in your brain!)
If you’d had more context before the word “jack”—maybe a story about who I am, my upbringing, my relationship with my parents, and my insecurities about being a generalist—you might have been more likely to predict “jack of all trades, master of none.”
So how do we get you to the right answer? If we just beefed up your smarts—let’s say, by throwing all of the computer power in the world into your brain—you still wouldn’t really be able to reliably predict “of” from just “jack.” You’d need more context to know which “jack” we’re talking about.
This is how language models work. Before the word that comes after “jack,” the models spend a lot of time interrogating it by asking, “What kind of ‘jack’ are we talking about?” They do this until they’ve narrowed down “jack” enough to make a good guess.
A mechanism called “attention” is responsible for this. Language models pay attention to any word in the prompt that might be relevant to the last word, and then use that to update their understanding of what that last word is. Then they predict what comes next.
This is the fundamental insight of language models:
There are far more words in the English language than you and I realize.
What you and I might see on a page is the word “jack,” but as an LLM, you’d see something else.
You’d have an invisible hyphen to your left with a bunch of extra words that you carry around—like a runaway kid with an invisible bindle:
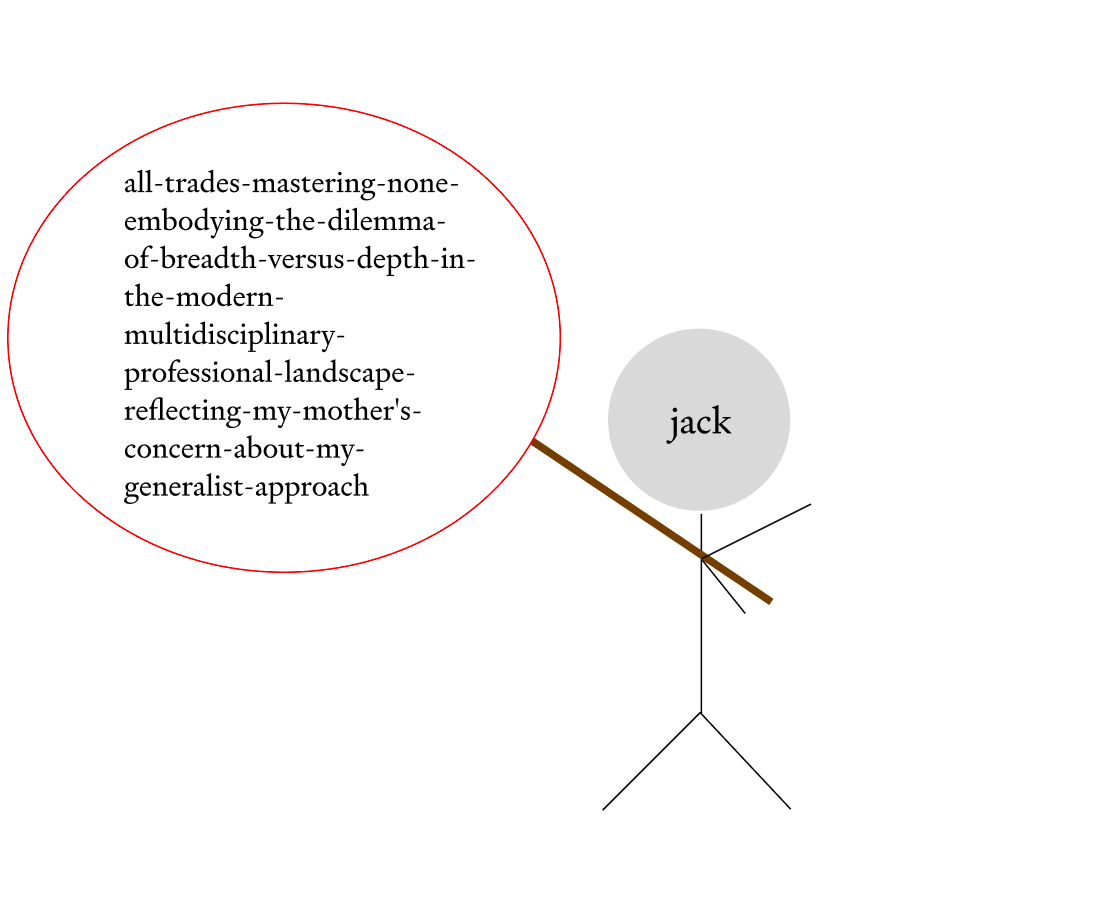
You will also encode things like the part of speech, whether or not the word occurs as part of a live chat, and zillions of other details that we might struggle to put into words.
As a result, it’s much easier to predict what comes next. This method takes “jack” and turns it into a far more specific word—let’s call it a Super Word—that looks something like:
“Jack-Nicholson-iconic-Hollywood-actor-with-a-legendary-smirk-known-for-The-Shining-his-Lakers-fandom-and-his-unsettling-charisma”
A much more complicated version of the above is probably a word that exists somewhere in GPT-4, and from that word, the model can produce a list of likely things that come next.
Now the question is: How does the model do this?
Language models have the biggest, baddest dictionary you’ve ever seen
During its training process, a language model creates a massive dictionary to contain all of these very complicated, made-up Super Words. It builds this dictionary by reading the whole internet and creating Super Words out of the concepts it encounters.
It does this with the same attention mechanism we discussed earlier: It examines text, piece by piece, to try to understand the statistical relationships between words in the text it encounters. It then encodes those as words in its dictionary of Super Words.
After training, when the language model gets a prompt, all it has to do is take the last word in the prompt and repeatedly ask: “What kind of word are you, really?” until it builds up a much more complex Super Word. Then, it looks up that Super Word in its massive dictionary, which helps it predict what usually comes after that. It repeats the process again and again: It combines the prompt and its one-word response, and calls itself again with that new prompt. It does this until it reaches a stopping point and returns an answer. The full response from the language model is a record of this journey.
Except there’s one problem. What if the model encounters a Super Word that isn’t in its dictionary? This could happen, for example, if words begin to occur together in a new way that the language model didn’t see in its training.
For example, it’s well known that Jack Nicholson is a Lakers fan. What happens if he suddenly renounces his fandom, becomes a Pacers fan, and moves to Indianapolis? It’s unlikely that a language model would’ve come across that while it was training, which makes it unlikely that it would have any Super Words representing Jack Nicholson as a Pacers fan in its dictionary.
This is bad! We never want our language model to fail if it encounters Super Words that it hasn’t seen before. It’s not a huge conceptual leap to make Jack Nicholson a Pacers fan instead of a Lakers fan. How can we build a dictionary that allows for this?
Language models have a beautiful solution. Their dictionaries are not composed of a list of words. Instead, their dictionaries work like a map.
Mapping language with math
New York City is laid out on a grid. If you start at 1st Street and walk north up 1st Avenue, you’ll eventually end up at 14th Street. If we made a dictionary of all of the streets between 1st Street and 14th, it would look something like this:
- 1st Street
- 2nd Street
- 3rd Street
- etc.
But there’s an entire block between 1st Street and 2nd Street with different stores and restaurants. And they’re changing all the time. The individual points on that block wouldn’t really fit into a list like the one above, even though they exist.
Instead, we lay out locations of stores and restaurants on a map. And we plot our own location using latitude and longitude. So we can move in smaller increments of direction than a grid of street names allows for.
This is what language models do with the Super Words that they keep in their dictionaries. As part of their training, they plot all of the Super Words that they create on a map. Words whose coordinates—or locations—are closer together are closer in meaning. But Super Words can also exist between any two points on a map, ust like you can visit any location between, say, 1st Street and 2nd Street, even if that particular address hasn’t been marked.
By representing Super Words as coordinates on a map, language models can “know” about words that fall between known points, even if those specific words were not present in the training data.
The wild part is that this map allows you to do math with meaning. Let’s go back to the word “jack.” If you move in any direction on the map, you’ll encounter different forms of the word. For example, there’s a direction on the language model’s map that corresponds to being an actor. The further you go in this direction, the more likely it is that the word you’re constructing refers to an actor.
There’s also a direction for being a musician, with the same property. The further you go in the “musician” direction, the more likely it is that the word refers to a musician. If you can subtract the “actor” direction from the word “jack” and add the “musician” direction, the Super Word you’re constructing is now much more likely to refer to “Jack Johnson” than it is to “Jack Nicholson.”
What language models tell us about language
The way language models work reveals some deep properties about the nature of language and reality.
They tell us that what comes next is a product of what comes before. Past is prologue, as Shakespeare said.
They also tell us that the way this works isn’t through a simple list of static rules. Instead, it happens in a continuous space of possibility, where each piece of what comes before contributes a little bit to the meaning of the word, and therefore to what comes afterward. Every bit of context matters.
As we saw, language models represent Super Words as locations on a giant map of meaning. The distance and direction between these locations capture the intricate relationships between words and concepts. This map is so expansive that even combinations not directly seen during training—like Jack Nicholson becoming a Pacers fan—can be navigated to by moving in the right “semantic direction.”
They also tell us that words are powerful. Every word we feed into a language model is actually a signpost pointing to a particular spot in this vast landscape of linguistic possibility. And the model generates what comes next by charting a path from that spot, guided by the subtle interplay of all the signposts that came before.
In that lies its power as a tool: Language models are only as good as the way we use them. Learning to use them well is a skill, and an art.
That should be exciting to anyone who wants to use them for creative work.
If you want to explore this topic further, here are some more resources:
Dan Shipper is the cofounder and CEO of Every, where he writes the Chain of Thought column and hosts the podcast AI & I. You can follow him on X at @danshipper and on LinkedIn, and Every on X at @every and on LinkedIn.
Find Out What
Comes Next in Tech.
Start your free trial.
New ideas to help you build the future—in your inbox, every day. Trusted by over 75,000 readers.
SubscribeAlready have an account? Sign in
What's included?
-
 Unlimited access to our daily essays by Dan Shipper, Evan Armstrong, and a roster of the best tech writers on the internet
Unlimited access to our daily essays by Dan Shipper, Evan Armstrong, and a roster of the best tech writers on the internet
-
Full access to an archive of hundreds of in-depth articles
-
-
Priority access and subscriber-only discounts to courses, events, and more
-
Ad-free experience
-
Access to our Discord community
Thanks to our Sponsor: Notion
Thanks again to our sponsor Notion, your connected workspace for everything. Startups can unlock 6 months of Notion Plus with unlimited AI, a $6,000 value—for free! Join thousands of startups using Notion to manage all aspects of their business, from engineering to onboarding to fundraising. Access AI capabilities to boost efficiency and scale your operations.
Get started with Notion Plus by selecting Every in the drop-down partner list, then entering code EveryXNotion.

 Dan Shipper
Dan Shipper


Comments
Don't have an account? Sign up!
This was an amazingly clear description! Thank you! I do wonder if this is really all there is to this process—or if there are emerging properties coming up, as you can see with complexity in nature. Take the "apple test" (which I've modified as a two-word combo such as this: Write ten sentences in which the fifth word is "apple" and the final word is "rosemary."); right now, only Claude 3 Opus passes my apple-rosemary test; why would other frontier models not do it too if they are just predicting the next word using huge dictionaries? Is there something else happening?
Plus, there is coherence to the outputs in a way that I find hard to see as just next-word prediction. On the Leaderboard, I tested two unknown models by presenting a hypothetical (at the time of the Louisiana Purchase, it turns out that Colombia bought the United States, so that the US is now a department of Colombia) and asked for a campaign poster for the 2024 election in the Department of the United States—what came up was brilliant; it's so hard to think it was just pieced word-by-word as opposed to chunked together with a clear sense of where the argument was headed down the line and not just after the space bar.
I'm often so amazed by these things that I find it hard to think of them as mere word predictors. Still, your explanation was really good! Thank you for that!
I commend you for attempting to explain such a complex topic in layman terms. As an ML practitioner a few things made me cringe but I'm also well aware I likely wouldn't be able to explain these concepts with zero technical terms.
I do want to touch up on one part, the "biggest, baddest dictionary you’ve ever seen". Perhaps I misunderstood, but you seem to be implying the model's vocabulary is created (or at least modified) during pre-training. That isn't the case. I'm actually not sure what you are referring to as "vocabulary" here, as some of the explanations seem to describe model weights behavior (vs. vocabulary words). I wonder if readers who haven't read any other "LLM 101s" might come out of this with erroneous assumptions.
Again, this is a solid attempt at simplifying the maths behind deep learning. I'd just recommend adding a disclaimer that this is quite simplified and the inner workings of LLMs are much more involved.