
At Every, we pride ourselves on being able to analyze and write at the speed of technology. We move quickly so that we can help our readers understand how the world around them is changing—possibly never more so than now, with AI transforming our world like no other technology of the past decade. But in order to do that, we need to take a deep breath every once in a while. So we’re taking another Think Week: We’ll be publishing some of our greatest writing on AI and giving our team the space to dissect the ideas, questions, and themes that captivate us so we can create a better product for you. On Monday, we debuted Michael Taylor’s new column, Also True for Humans, which examines how we manage AI tools like we would human coworkers. This week we’re republishing some of Mike’s most trenchant Every pieces, starting with this one about why evaluating AI tools is so important. —Kate Lee
Was this newsletter forwarded to you? Sign up to get it in your inbox.
To paraphrase Picasso, when AI experts get together, they talk about transformers and GPUs and AI safety. When prompt engineers get together, they talk about how to run cheap evals.Evals, short for “evaluation metrics,” are how we measure alignment between AI responses and business goals, as well as the accuracy, reliability, and quality of AI responses. In turn, these evals are matched against generally accepted benchmarks developed by research organizations or noted in scientific papers. Benchmarks often have obscure names, like MMLU, HumanEval, or DROP. Together, evals and benchmarks help discern a model’s quality and its progress from previous models.
Below is an example for Anthropic’s new model, Claude 3.
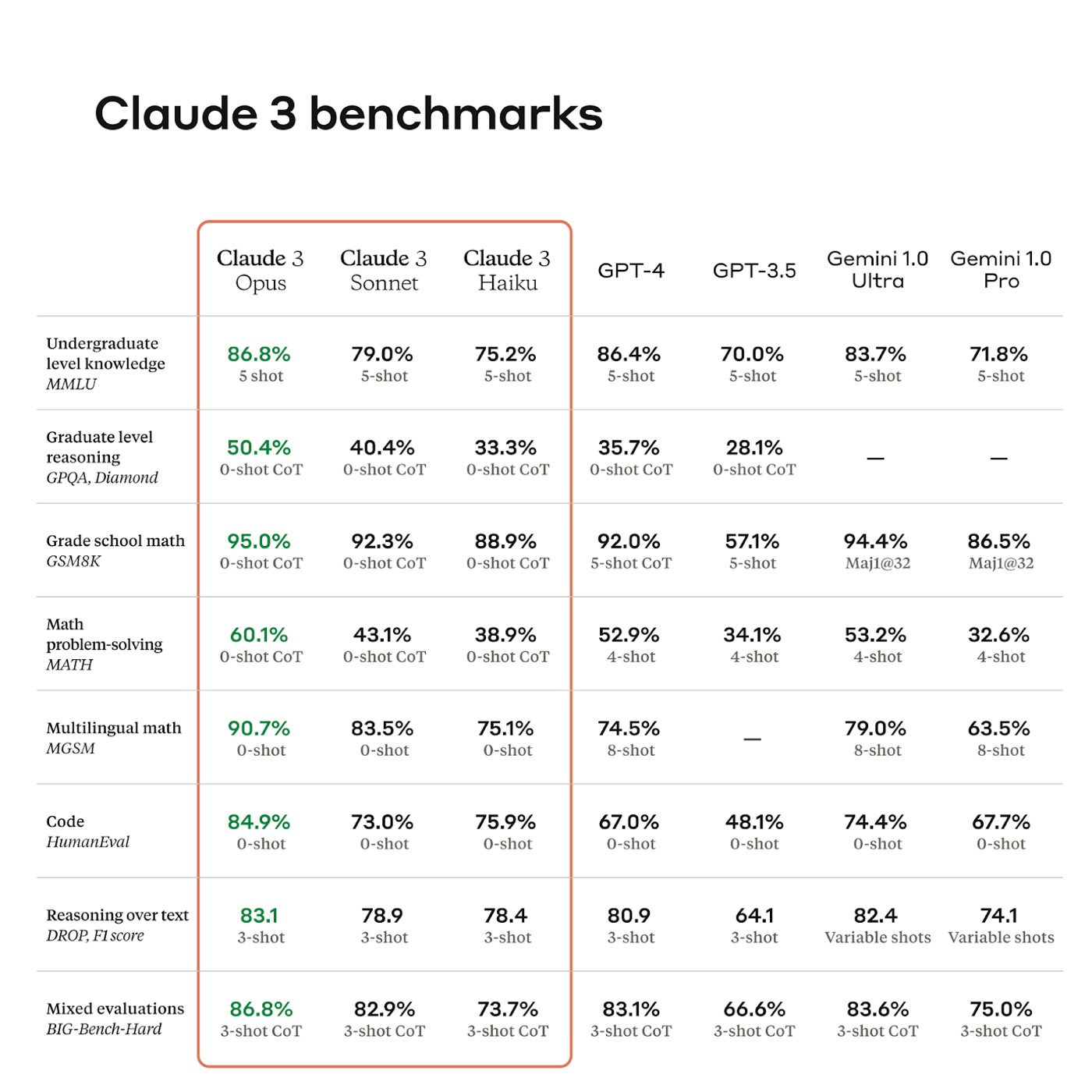
And even though head-to-head comparison rankings—where the results of two models for the same prompt are reviewed side-by-side—use real humans and can therefore be better, they’re not infallible. With Google Gemini able to search the web, it’s like we’re giving the AI model an open-book exam.
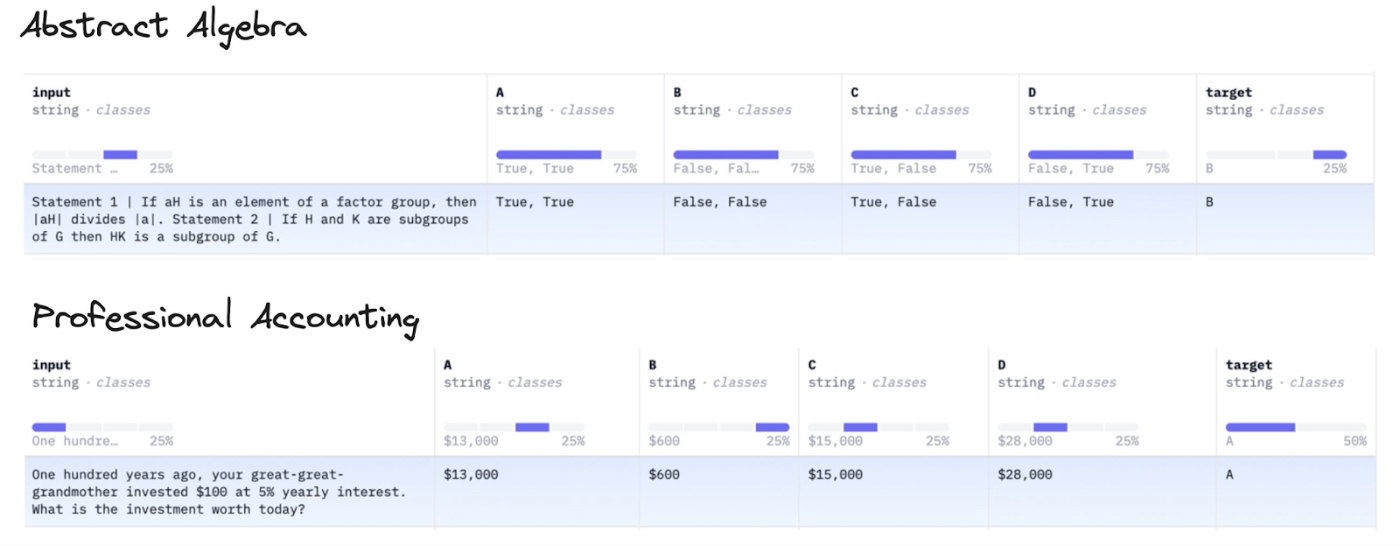
In this piece, we’ll explore how to get started with evals. We’ll touch on what makes evals so hard to implement, then run through the strengths and weaknesses of the three main types of eval metrics—programmatic, synthetic, and human. I’ll also give examples of recent projects I’ve worked on, so you can get a sense of how this work is done.
What makes evals so hard to implement?
Become a paid subscriber to Every to learn about:
- The AI eval trifecta: Programmatic, synthetic, and human
- Why evals matter more than benchmarks for real-world AI applications
- The challenges of implementing effective AI evaluation metrics
- Lessons from the trenches: A prompt engineer's guide to practical evals
Find Out What
Comes Next in Tech.
Start your free trial.
New ideas to help you build the future—in your inbox, every day. Trusted by over 75,000 readers.
SubscribeAlready have an account? Sign in
What's included?
-
 Unlimited access to our daily essays by Dan Shipper, Evan Armstrong, and a roster of the best tech writers on the internet
Unlimited access to our daily essays by Dan Shipper, Evan Armstrong, and a roster of the best tech writers on the internet
-
Full access to an archive of hundreds of in-depth articles
-
-
Priority access and subscriber-only discounts to courses, events, and more
-
Ad-free experience
-
Access to our Discord community

 Michael Taylor
Michael Taylor

